Google MapReduce
无论是出于对分布式系统的兴趣,还是对一个未来的 Hadooper 来说,这篇论文都值得一读。号称为 Google “三驾马车”之一,同时也作为6.824 LEC 1的 preparation, 其重要性也随之体现。趁着时间充裕,抓紧读了读并尝试着手进行后面的 lab。
概念
Google 提出了一种 Map-Reduce 的模型。map 将一对键值对处理成另外一组中间键值对, reduce 将这些中间键值对中 key 相同的合并起来。 系统关注的除了处理数据本身之外,还有调度机器之间程序的运行、处理机器故障以及管理机器之间的通信。
编程模型
就如前面提到的,用户编写的 Map 将所有的输入处理成中间状态的键值对,MapReduce 根据中间状态的 Key 将其整理到一起(因为数据在不同的机器上),并将其交给 Reduce。
之后,同样是用户编写的 Reduce 将 Key 相同的中间键值对合并到一起。合并的数据集可能只是一小部分。
下面是一个单词计数的例子:
map (String key, String value)
// key document name
// value document content
for each word w int value:
EmitIntermediate (w, "1");
reduce (String key, Iterator value)
// key a word
// values a list of counts
int result = 0;
for each v in values:
result += ParseInt (v);
Emit(AsString (result));
map 函数将出现过的单词与其出现过的次数相关联,这里是1。 reduce 函数将相同单词出现的次数求和。
比如,输入以下数据
hello Java
hello C
hello Java
hello C
map 将其处理之后,变成
hello 1
Java 1
hello 1
C 1
hello 1
Java 1
hello 1
C 1
其间通常会对这些数据进行 shuffle
hello 1
hello 1
hello 1
hello 1
Java 1
Java 1
C 1
C 1
最后,reduce 将这些数据合并
hello 4
Java 2
C 2
实现
执行过程的概括
输入数据被自动分成 M 份,然后分发给不同的机器上进行 map 处理。中间状态的 Key 被分成 R 份(比如 hash(key) mod R),然后被不同机器进行 reduce。其中 R 是由用户设置的。
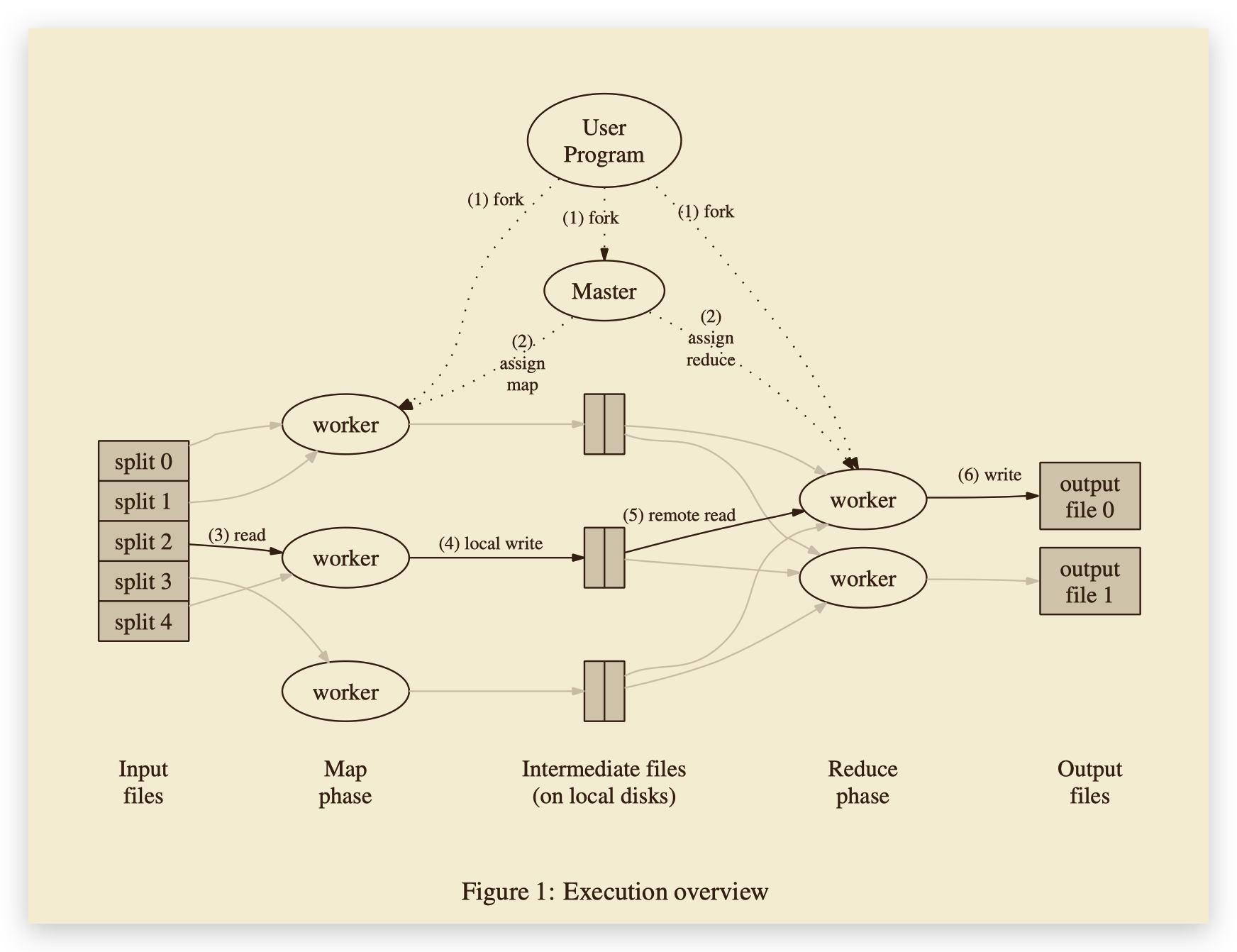
MapReduce 首先将输入数据分成 M 份,之后在许多机器上启动 MapReduce 程序。其中有一个特殊的 master,它给其他的 workers 分配工作。共有 M 个 map 和 R 个 reduce 任务,master 将其中之一分配给空闲的 worker。map worker 读取输入文件,生成的中间键值对被缓存在内存中,这些中间键值对被定期地写入硬盘。worker 将这些数据的存储位置告诉 master,master 负责将这些位置告诉 reduce worker 以便其处理。reduce worker 得知这些地址以后,发起远程过程调用从 map worker 的硬盘上读取中间键值对,并在处理完成后将结果附加到输出文件中。
简单来说,就是 master 将任务分配给 map 和 reduce 两种 worker。map worker 处理完成之后存在本地,master 通知 reduce worker 来读取数据并处理。
Master 的数据结构
对于每个 map 和 reduce woker, master 需要储存他们的状态(空闲,正在处理,已完成),每个工作中的 worker 的标识。同时,master 也是中间数据从 map 到 reduce 传输的渠道。所以 master 也要储存其位置和 R 个中间键值对的大小。这两个数据在 map 完成时更新,之后被增量同步到 reduce 那里去。
我的一种实现:
type Master struct {
/*
each map and reduce task has a *state*: idle, in-progress, or completed
here assigns:
0 idle
1 in-progress
2 completed
3 failed
worker identity - status
*/
State map[string]int
/*
identity of each worker
*/
/*
a work request *one* job, read *one or more* input files,
write the task's output to *one or more* files
to simplify, each task may have one or more input files,
but one input file matches one output file
intermediate file locations from map worker to reduce workers
*/
Locations []string
//sizes of the R intermediate file regions produced by map task
Sizes []string
}
容错
Worker
master 定期向 worker 发送心跳包,当一定时间时候如果没有收到回复,master 就会将其标记为 failed。所有该 worker 执行、完成的任务都会被其他 worker 重新执行(reduce worker 完成的除外,它的输出以及被存在 GFS 上了)。如果一个 map worker 执行的任务失败了并由其他 worker 接手,那么正在执行的 reduce 任务都会被重新执行。
Master
master fail 后会启动一个新的 master,从最新的检查点继续执行。
论文中需要注意的细节
- 一个执行中的任务将其输出写入临时文件中。一个 reduce worker 产生一个这样的文件,一个 map 任务产生 R 个这样的文件(一个文件对应一个 reduce 任务)。
- 当一个 map 任务完成之后,worker 发送给 master 消息,包括 R 个临时文件的名称。如果 master 重复收到 map 任务的消息,那么就会忽略它。否则就记录在数据结构中。
- 当一个 reduce 任务完成之后,reduce worker 自动把它的临时输出文件重命名为最终的输出文件。如果 reduce 被多个机器执行的话,同一个最终输出文件的多个重命名操作就会执行。
- master 会根据数据在 GFS 中的位置来调度,以此来提高效率。
- 当整体任务接近完成时(剩下最后几个任务),MapReduce 会执行多个后备任务。当其中有一个完成时,就标志该任务完成了。
优化
中间状态键值对被分成多份数据。在同一份数据中,键值对是以 Key 的顺序排列的(上面提到的 shuffle)。
可以看出,除去与分布式系统部分相关的功能来说,这个系统很容易理解。需要关注的点在 map 和 reduce 的处理(但这实际上是用户负责编写的),master 与 worker 之间的 RPC 及任务调度上。但是被忽略掉的往往就是最关键的的共识机制,而分布式系统的魅力也在于此。