Spark Papers
Spark: Cluster Computing with Working Sets
MapReduce (下称 MR)任务包含主要五两个步骤:Map、Sort、Combine、Shuffle、 Reduce,每个 MR 任务在 Map 将数据阶段将数据转换成 K-V 的形式;Reduce 在不同的机器上作聚合运算。Shuffle 更是涉及到巨大的 I/O 操作(主要是网络 I/O)。每个 MR 任务最终会将计算结果写回存储系统。
由于 MR 任务的最终结果会写回存储,那么有两种经典场景对于它来说是低效的:
- 迭代任务(迭代机器学习算法)
- 交互式数据分析工具
Spark 提出了 RDD (Resilient Distributed Dataset) 模型来处理此类问题。RDD 是一个被分布在一组机器上的只读的对象集,当一个分区丢失时 RDD 能够很快通过重新计算的方式来重建。RDD 能够被保存在内存中,并以类似 MR 的 *并行*操作方式 得到重用。RDD 通过一种叫做 血统(lineage) 的概念实现容错:如果 RDD 的一部分丢失了,那么 RDD 有足够的信息(该 RDD 是怎么从其他 RDD 计算出来的)来重建该部分。
在 Spark 中,RDD 以 Scala 对象的形式存在。并且 RDD 能够通过以下几种形式构造出来:
- 来自共享文件系统(如 HDFS)中的一个文件
- 并行化(parallelizing) 一个 Scala 集合
- *转化(transforming*)于一个已经存在的 RDD
- 改变一个已存在 RDD 的持久性(persistence)
- *cache*:将 RDD 暂存于内存以便稍后重用
- *save*:将 RDD 存于类似 HDFS 的分布式文件系统
对于 cache 这种情况来说,如果集群中没有足够的内存来缓存一个数据集(dataset)的所有部分,那么 Spark 会在使用它们时重新计算。
通常来说,当一个函数被传递给 Spark 操作(Spark operation)到一个集群中时,该操作会在这个函数中所有变量的多份副本上执行。这些变量被复制到各个机器上,但对这些变量的更新不会再传播回到驱动程序(driver program)上。而对共享变量的读/写是低效的。所以:
Spark 允许用户创建两种受限制的*共享变量(shared variables)*来支持两种简单但常见的用法:
Broadcast variables
广播变量允许开发者将一个只读的变量缓存在每台机器上,而不是随着任务传输一个副本。对于共享变量来说,只有在多个阶段需要同样数据的情况才是一个高效的使用方式。
Accumulators
累加器通常可以用来作计数器。每个累加器在创建时得到一个独特的 ID,在 workers 上,累加器在每个线程上创建一个线程本地(thread-local)变量。当一个任务开始时被重置为0,workers 将其发送给驱动程序让其累加。
Spark 实现的核心是 RDD,举个🌰
val file = spark.textFile("hdfs://...")
val errs = file.filter(_.contains("ERROR"))
val cachedErrs = errs.cache()
val ones = cachedErrs.map(_ => 1)
val count = ones.reduce(_+_)
这些数据集将会以一组对象的链路存储,也就是 RDD 的血统, 如图1所示。每个数据集对象包含一个指向它父亲的指针和对它是如何从它父亲那里计算出来的说明。
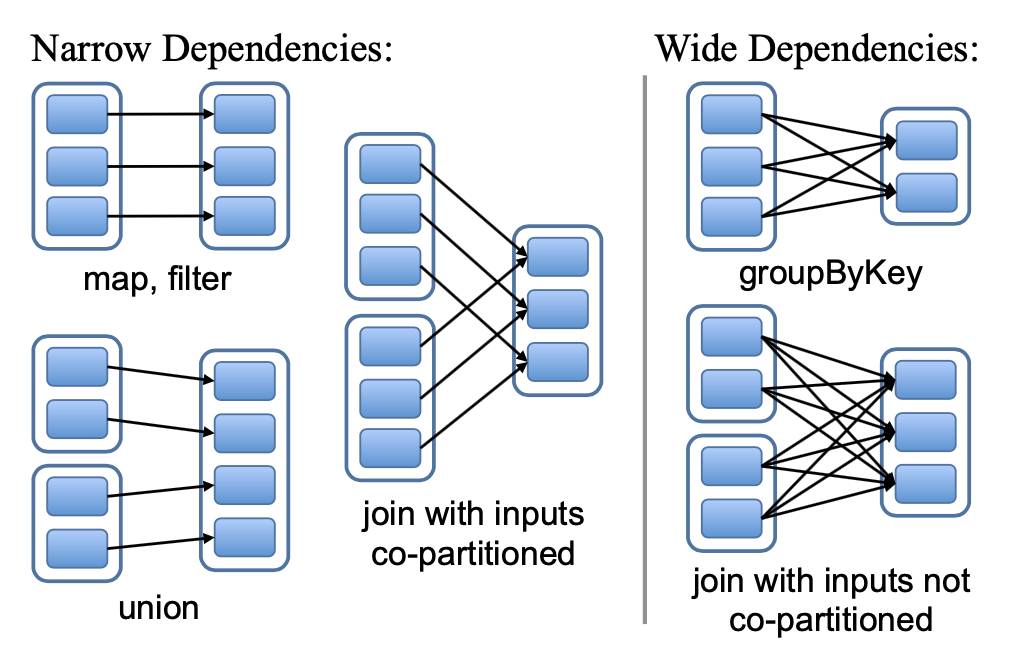
图1,RDD 对象的血统链路
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
RDD 因当前(Spark 诞生前)计算框架对迭代算法和交互式数据挖掘工具支持的低效而诞生。这两者的共同点是都将数据保存在内存中,以此来提高性能。RDD 提供基于粗粒度的转换(transformations)的内存模型,而不是细粒度的对共享内存的更新。
对于之前已有的框架来说,尽管能够利用集群的计算资源,但是缺少对集群内存的使用。这使得能够*重用*中间结果的应用变得低效。
设计 RDD 的最大挑战是能够提供*容错*和*高效*的编程接口。对于已有的集群内存存储的抽象,例如分布式共享内存(DSM)、K-V 存储、数据库和 Piccol,它们提供了一个细粒度的基于对可变状态的更新的接口。这种接口提供容错的仅有方式是:
- 将数据备份到不同机器上
- 在机器之间更新日志。
这两种方式对于数据密集型任务来说是很昂贵的,因为它们都需要在集群间复制大量的数据。而这种集群的网络带宽要比内存小得多。
和这些系统相比,RDD 提供了基于粗粒度的转换(transformations)的接口。通过记录构造 RDD 的血统关系而不是数据本身来提供容错性。若 RDD 的一部分丢失,那么有足够多的关于它如何从其它 RDD 转换过来的信息来重新计算这个部分。
RDD 是一个只读的分散(partitioned)记录。它能从对
- 稳定存储
- 其它RDD
的操作得到。
这种操作被叫做 transformations 以来区分对 RDD 的其它操作。
同时,用户能够指定 RDD 的重用、存储策略,根据实际需要将 RDD 划分开(partitioning)。用户能够“持久化” RDD,并将其存储在内存中,当内存不足时可以根据策略落盘或进行其它操作。尽管 RDD 是不可变的,但是可以通过多版本 RDD 来间接实现 RDD 的可变性。
RDD 与分布式共享内存(DSM)的主要区别在于 RDD 只通过粗粒度的变化(transformations)来创建(对于 RDD 的读仍然是细粒度的),而 DSM 允许在每个内存区域中读写。由于 RDD 通过其血统实现容错,故它不需要检查点(checking point)。此外,只有丢失的部分才会被重新计算,并且丢失的部分可以被许多机器并行地计算。
RDD 的另一个好处在于它的不可变性,这个特点让系统通过在其它节点上执行慢任务的副本来减轻慢节点(stragglers)的情况,这个做法和 MR 类似。但是这在 DSM 中很难实现,因为它同个任务的两个副本会访问同一块共享内存。归功于局部性原理,可以将任务调度在同一个节点上(或类似的做法)来提高性能。
对于 RDD ,它适用于对数据集中应用相同操作的批处理;而不适用于对共享状态的异步细粒度更新。
理想上来说,实现 RDD 的系统应该提供丰富的转换操作集合,并且能够让用户自由地组合它们。实际上 RDD 的实现是通过一个简单的基于图的方式做到的。简要来说,RDD 是通过以下五点做到的:
- 一组部分(a set of *partitions*)
- 父 RDD 的一组依赖(a set of dependencies on parent RDDs)
- 基于父 RDD 的计算函数(a function for computing the dataset based on its parents)
- 分散方案的元数据(metadata about its partitioning scheme)
- 数据存放的位置(data placement)
描述 RDD 之间的依赖的一个有效方法是将其分为两种类型:
narrow dependencies
每个父 RDD 的一个 partition 只被至多一个子 RDD 的一个 partition 使用
wide dependencies
多个子 RDD 的 partitions 依赖父 RDD 的 partition
由于 narrow dependencies 的依赖关系十分简单(一对一依赖),故它能够在一个节点上以流水线的方式执行。而 wide dependencies 则需要类似 shuffle 的操作。同理,对 narrow dependencies 节点的恢复也更简单。
针对 wide denpendencies,目前采用在节点上存储中间记录的方式存储父 partitions,以此来简化容错。
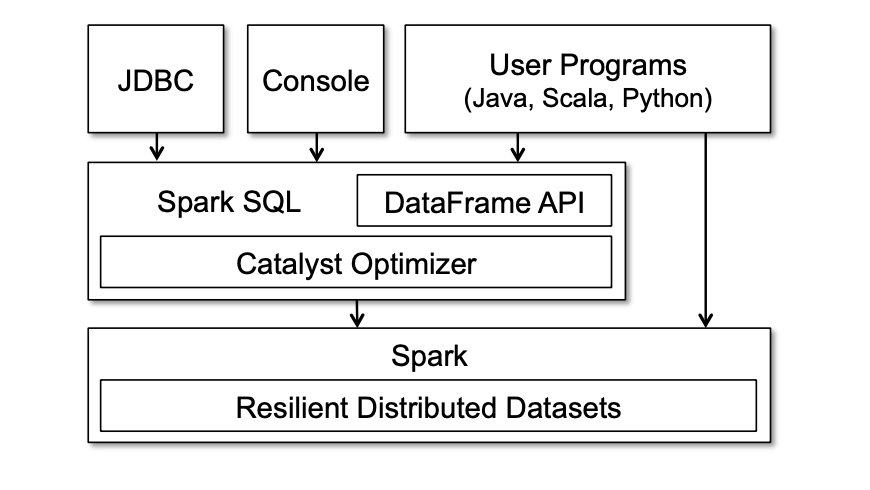
图2,narrow dependencies 和 wide dependencies 的示例。每个方格是一个 RDD,阴影矩形是 partitions
当 RDD 的血统特别长或依赖特别宽时,恢复 RDD 变得昂贵。这时提供检查点的方式来降低开销,Spark 可以从最近的检查点开始恢复来最小化系统的恢复时间。RDD 的不可变性使得检查点容易实现,因为它不会带来并发安全问题。
Spark SQL: Relational Data Processing in Spark
受益于 Spark SQL,Spark 能够借助关系处理的优点,同时让 SQL 用户体验到强大的 Spark 类库。与其它系统相比,Spark SQL 提供了关系性和程序处理的紧密结合——通过陈述式的 DataFrame API。其次,它引入了一个叫做 Catalyst 的高扩展性优化器。
Spark SQL 通过 DataFrame API 在外部数据源和内建分布式集合之间建造起了桥梁。DataFrame 是能够通过使用 Spark API 来操作的数据结构集合,它能够直接通过 Java/Python 对象来创建。
构建 Spark SQL 的原因在于:
- 提供用户友好的 API 在 Spark 程序内部和外部数据源上支持关系化处理
- 使用建立 DMBS 的技巧来提供高性能
- 易于支持新的数据源,包括半结构化数据和外部数据源
- 能够扩展高级分析算法(如图处理和机器学习算法)
Spark 暴露出了一个 SQL 接口,能够通过 JDBC/ODBC 的形式访问,此外也能通过 Spark 支持语言的 DataFrame API 访问,如图3。
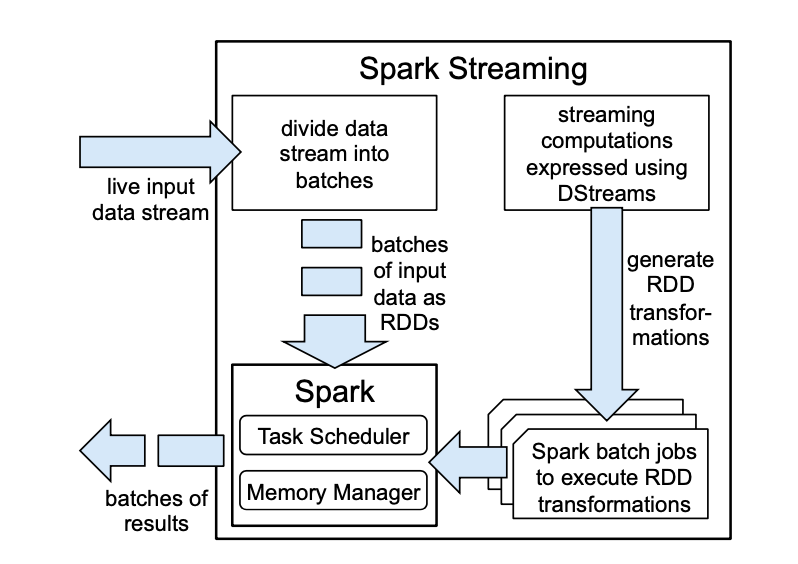
图3,Spark SQL 接口和与 Spark 的交互
对 Spark SQL API 的主要抽象是 DataFrame,它是相同 schema 下 row 的分布式集合。一个 DataFrame 与关系型数据库中的一张表是等价的。并且它能够以 RDD 相似的方式来操作。与 RDD 不同的是,它会追踪他们的 schema 并且支持多种能够优化的关系性操作。
DataFrame 可以从外部数据源的表中构造出来,也可以通过已经存在的 RDD 得到。DataFrame 是惰性的,只有在用户调用特殊的输出操作才会真正的执行,因为这样能够充分地利用优化器的特性。
DataFrame 能够注册作为临时表并执行查询。
users.where(users("age") < 21)
.registerTempTable("young")
ctx.sql("SELECT count(*), avg(age) FROM young")
这种特性能够让他在内存中执行聚合操作。
与 ORM 框架相比,ORM 框架会将整个对象转换成不同的格式。而 Spark SQL 只会在每次查询中在原地访问所需的列。这种访问原生数据集的能力能够让用户在 Spark 程序中执行优化过的关系操作。此外,也能让 RDD 与外部结构数据的结合更简单。(实现不同数据源之间的关联)
case class User(name: String, age: Int)
// Create an RDD of User objects
usersRDD = spark.parallelize(
List(User("Alice", 22), User("Bob", 19)))
// View the RDD as a DataFrame
usersDF = usersRDD.toDF
views = ctx.table("pageviews")
usersDF.join(views, usersDF("name") === views("user"))
Discretized Streams: Fault-Tolerant Streaming Computation at Scale
许多大数据应用以实时的方式来进行计算,而已有的流式计算模型(D-Streams 之前的)只能提供昂贵的容错方式。为了克服这些困难,D-Streams 提供了一个并行恢复的机制来提高传统副本和备份方式的效率,同时解决了掉队者(计算较慢的节点)的问题。
设计这个模型的两个巨大挑战是:
- 错误
- 掉队者(慢节点)
这两个问题在大集群中都是不可避免的。流式应用必须快速地恢复,因为每一秒延迟恢复意味着大量数据处理的丢失。
不幸的是,已有的流处理系统很难处理错误和掉队者。大多数分布式流处理系统如 Storm、TimeStream、MapReduce Online 和流式数据都是基于连续算子(continuous operator)模型构建的。这种模型通常长时间运行,有状态的算子接受每条记录、更新其内部状态、并且发送新记录。这些模型过于简单,很难处理错误和掉队者。
通常对于连续算子模型来说,系统恢复有两种方式:
副本(replication)
每个节点上放两个副本
上游备份(upstream backup)
发送节点缓存发送的消息,当下游失败时重发
这两种方式对大型集群来说都不够友好:
副本需要至少两倍的硬件;而上游备份需要很长时间来恢复,整个系统需要等待一个新节点按顺序通过重新运算来重建失败节点的状态。
此外,这两种方式都没有处理掉队者的情况:
在上游备份方式中,掉队者必须作为*失败*的情况来处理,增加了一个恢复的步骤;备份系统使用像 Flux 的同步协议来协调副本,所以一个掉队者会使副本都变慢。
副本(replication)是数据库常见采用的形式。此种情况在处理图中有两个副本, 并且输入记录被发送到这两处。简单做副本是不够的,系统同样需要*同步协议来*保证每个算子的两个副本以相同的顺序看到上游数据,因为相同的顺序产生相同的输出流。尽管能够快速地从失败中恢复,副本也是代价很高的。
在上游复制中,每个节点保存从某个检查点开始发送的消息副本,当节点失败时会有机器替代它,上游会将消息发送来让其重建。这种方式会导致很长的恢复时间,因为一个节点必须通过重新计算一系列有状态的算子代码来恢复它丢失的状态。
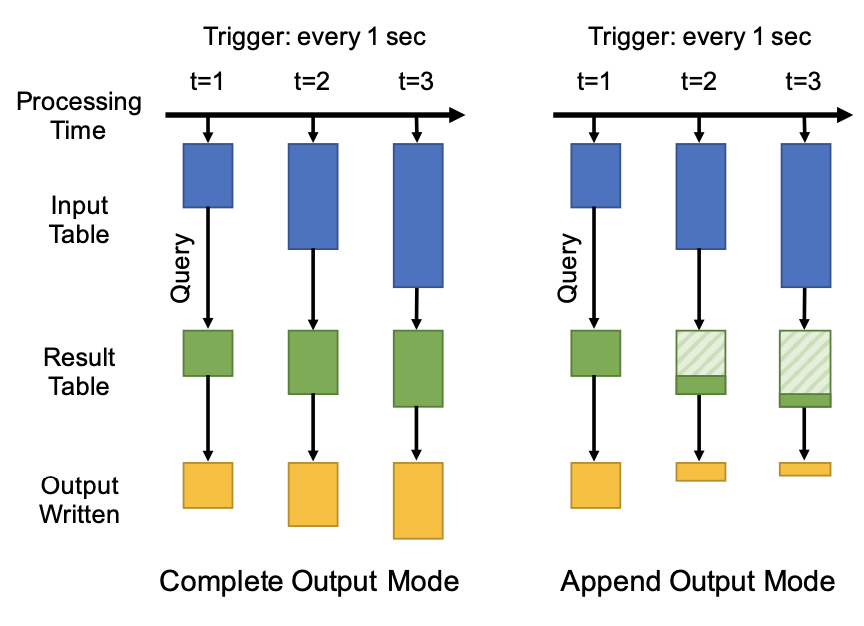
图4,Spark Streaming 的高层次概览
D-Streams 克服了这些问题。舍弃管理长活的算子,它构造了一组短时间间隔上无状态、确定性的批计算作为一个流计算。为了实现这样的模型,D-Streams:
- 给定输入数据的情况下可以完全确定每个时间步的*状态*,从而无需同步协议
- 能以精细粒度看到此状态与较早数据之间的依赖
实现 D-Streams 有两个挑战:
第一个是降低延迟(时间间隔粒度)。传统的批处理系统通过将状态存在副本中来实现,而 D-Streams 是通过 RDD 做到的。
第二个是快速地从失败和掉队者中恢复。D-Streams 提供了一个新的恢复机制来实现:*并行恢复*丢失节点的状态。当一个节点失败时,集群中的每个节点都重新计算 RDD 的每一部分,在没有副本的消耗的同时,这也要比上游备份要快得多。对于掉队者,D-Streams 用猜测执行的方式来恢复,这在之前提到的流式系统中没有处理过。
D-Streams 将流计算看作一系列对小时间间隔的确定批处理计算。每个时间间隔接收到的*输入数据集*被可靠地存放在集群中。一旦时间间隔结束后,这个数据集通过像 *map*、reduce 和 groupBy 这样的确定的并行操作被处理掉来产生代表输出或者中间状态的新数据集。对于前者,结果可能被存储到外部存储中;而后者以 RDD 的形式存放。
D-Streams 是一个不可变的、分割开的数据集序列,它能被施加以确定的*转化(transformations)。*这些转化产生新的 D-Streams,也可能创建 RDD 的形式的中间状态。
D-Streams 根据每个记录到达系统的时间来将其放入输入数据集中。因为需要保证系统总是及时地开始一个新的批次,并且让应用能够在同一位置生成记录。
由于 D-Streams 主要是一个执行策略(描述如何将一个计算分成小步),它们可以用来实现许多流式的标准操作。
D-Streams transformations 和 output operation 与 RDD 类似。此外还提供了几个有状态的转化(transformations)。
Windowing
将一段时间窗口内的记录组合起到一个 RDD 中
Incremental aggregation
按时间窗口聚合
- State tracking
追踪状态的变化
D-Streams 的一致性机制非常简单,因为时间能自然地离散到时间间隔上,每个时间间隔输出的 RDD 反映这个和上一个时间间隔的所有输入。这在无论输出和状态 RDD 是否被分散到集群中都是一样的。
D-Streams 与其它持续算子系统的区别在于它将任务分割成小的、确定的批任务。尽管提高了延迟下限,但是能够高效地恢复。
Structured Streaming: A Declarative API for Real-Time Application in Apache Spark
借助于 Spark Streaming 的成功经验,Structured Streaming 在 API 上做了一定层次的升华。首先,它是一个基于自动递增静态关系查询的纯声明式 API,与要求用户构建 DAG 物理算子的 API 形成鲜明对比;其次,Structured Streaming 致力于支持将流与批处理和交互式分析集成*端到端*的实时应用。这种集成通常是一个重大挑战。
Spark Streaming 遇到的问题:
- 需要用户去考虑复杂的物理执行概念
- 只关注于流计算,但实际应用上经常与批处理分析、与静态数据的关联和交互式查询
为此,Structured Streaming 提供了两种形式的 API:
增量查询模型
Structured Streaming 通过 Spark SQL 和 Spark batch API 来表达静态数据集上的自增查询,这意味着用户只需理解 Spark batch 的 API 就能写出一个流式查询。
支持端到端的应用
此外,Structured Streaming 采取了几个手段来简化操作。第一,Structured Streaming 重用 Spark SQL 执行引擎,包括它的优化器和运行时代码生成器。第二,设计了一个支持失败、代码更新和重计算输出数据的引擎。比如,新数据的到来导致应用崩溃,更可怕的情况是输出了错误的数据。在 Structured Streaming 中,每个应用维护一个易懂的 JSON 格式 write-ahead event log,管理员能够使用它们在任意时间重启应用。如果应用由于自定义的函数(UDF)崩溃了,管理员能够更新 UDF 并让应用在跌倒的地方爬起来。若输出了错误的结果,也能手动回滚到问题发生之前。
由于其复杂的 API,流式应用要比批处理难用是共识。还有些新需求如:在收到全部数据之前,系统应该输出什么样的中间结果?由于流式 API 天生的*低级*特性,它们经常要求用户在复杂的物理算子而不是更陈述式的层面上明确系统。其它诸如 Google Dataflow 模型,需要用户为每个聚合算子指定一个 windowing mode、triggering mode 和 trigger refinement mode 来确定算子是输出增量还是累加结果。而像 Spark Streaming 和 Flink 的 DataStream API,需要编写一个物理算子的 DAG,并提供一系列管理状态的复杂操作。Structured Sreaming 使用其增量查询模型,在设计该模型的同时,发现在模型中增加定制的*有状态处理*算子也会让高级用户构建他们自己的处理逻辑。
几乎所有的流式工作都在大型应用的环境下运行,这种情况经常需要很大的工程负担。许多流式 API 只需要关注从一端读并写到另一端,而端到端的商业应用需要进行其它任务:
- 对新数据的交互查询
- ETL 任务需要将流与其它存储系统或批计算的数据连接(join)
- 需要将流式业务逻辑以批处理的形式运行
部署流式应用的巨大挑战之一是管理和操作,已知问题包括:
- 失败
- 代码更新
- 扩展性
- 掉队者
- 监控
除了操作和工程问题之外,流式应用的性能也是其一大问题,因为它总是以24/7的状态运行的。若没有动态扩展,在波峰之外的时间应用会浪费大量的资源。即使有了扩展性,持续计算也比周期批处理的任务要昂贵。为此,Structured Streaming 借助了 Spark SQL 中所有的执行优化。性能的首要优化项是*吞吐量*,因为它是大型流式应用中的重要指标。
Structured Streaming 连接了一组输入输出源。为了提供“恰好一次”输出和容错,它在输入和输出上给出了两个限制:
- 输入必须是*可重复的(replayable)*,当节点崩溃时允许系统重读最近的输入
- 输出必须支持*幂等*写,确保写时节点崩溃能够可靠恢复。若下游输出目标支持,Structured Streaming 能提供原子性的输出。即使是多个节点并行工作,整个任务的输出也应展现成是原子的
除外部系统外,Structured Streaming 也支持 Spark SQL 的输入和输出。用户能从任意的 Spark 批输入源计算一个静态表,也能将其和一个流连接。或是让 Structured Streaming 输出成一个内存中能交互式查询的 Spark 表。
Structured Streaming 以两种形式的持久化存储实现容错。
- 通过 WAL 来追踪哪个数据被处理,每个输入源的 WAL 被可靠地写入输出
- 系统使用一个大型*状态存储*来保存长期运行聚合算子状态的快照
这两种都可以存储在可插拔的存储系统中。
Structured Streaming 的语义如下:
- 每个输入源根据时间提供一组部分有序结果(如来自 Kafka 的不同 partition)
- 用户提供一个查询,它在能够在输入数据之间执行,该输入数据能在任何处理时间点输出一个结果表
- 触发器(Triggers) 告诉系统何时去运行一个新的增量计算,何时更新结果表。
- 下游的*输出模式*明确了结果表如何被写入输出系统。目前支持三种模式:
- *Complete*:一次将结果写入
- *Append*:只向下游添加记录
- *Update*:根据每个记录的 key 来更新下游
图5阐述了这个模型,结果表的内容逻辑上只是一个永远不会物化的视图。
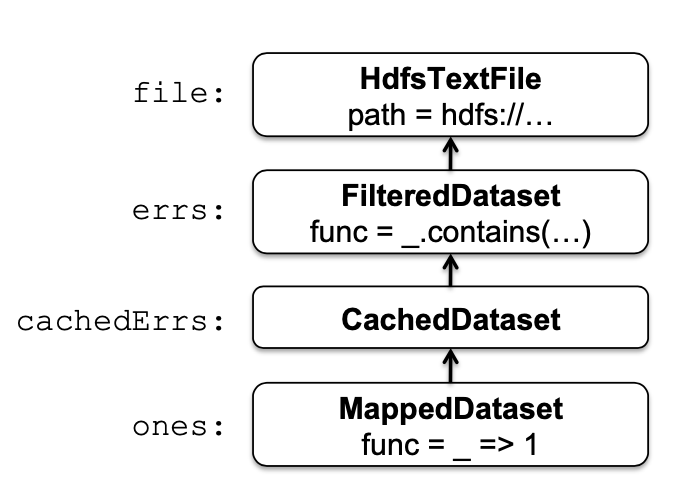
图5,Strucutred Streaming 两种输出方式的语义
该模型的第二个吸引人的特性是它有强大的一致性语义,叫做前缀一致性(prefix consistency)。
首先,它保证在一个输入源中输入记录相对有序时,输出被合并到相同的记录中。其次,由于结果表是基于输入前缀中的所有数据一次定义的,结果表中所有的行都对应到输入记录上。