Paxos vs Raft: Have we reached consensus on distributed consensus?
by Heidi Howard, Richard Mortier摘要
分布式一致性是构建具有容错、强一致性特点的分布式系统的重要原语。在众多分布式公式算法中,其中有两个统治着生产系统:经典、也是以晦涩难懂著称的 Paxos;较新的、与 Paxos 相比更易理解的 Raft。
本文主要研究 Paxos 和 Raft 那个是更好的分布式一致性解决方案。我们通过使用 Raft 的术语和语用抽象来描述简化的 Paxos 算法,从而对两者进行精确分析,以确定它们之间的区别。
我们发现 Paxos 和 Raft 都采用相似的方式来达成分布式一致性,它们之间的区别只在于 leader 选举。最值得注意的是,Raft 只允许有最新日志的节点成为 leader,而 Paxos 允许任何节点成为 leader,前提是之后更新其日志来保证为最新。对于这样的简单性来时,Raft 的方法出奇的高效,因为与 Paxos 不同,它在 leader 选举时不需要日志条目的交换。我们推测,Raft 的可理解性大多来自于论文的清楚陈述,而不是展现出的基本算法的基础。
*CCS 概念*:计算机系统管理→可靠性;软件及其工程→云计算;计算理论→分布式算法
关键词:状态机复制,分布式一致性,Paxos,Raft
1 简介
状态机复制[32]广泛用于将一群不可靠的主机组成一个可靠的能够提供强一致性保证包括线性化[13]的服务。据此,程序员能够通过复制状态机将服务看作一个单点系统,从而轻松推断出预期的表现。状态机复制需要每个状态机以相同的顺序接受相同的操作,这可以通过分布式一致性实现。
Paxos 算法[16]与分布式一致性关系密切。虽然它很成功,但是 Paxos 晦涩难懂,造成了其难以推理、正确实现和安全优化。这已经在无数次用更简单的术语解释算法的尝试[4, 17, 22, 23, 25, 29, 35]中得到明显体现了,而且这也是 Raft[28] 的目的。
Raft 的作者声称 Raft 与 Paxos 同样高效而更易懂,因此为实现具体系统提供了更好的基础。Raft 以这三种不同的方式来寻求实现这点:
演示 首先,Raft 论文引入了一个描述在状态机复制上下文中基于 leader 选举的一致性的新抽象。 事实证明,这种务实的演示在工程师中非常受欢迎。
简单 其次,Raft 算法的优先考虑简洁性而不是性能。例如,Raft 按顺序决定日志条目而 Paxos 允许乱序决定,但需要额外的协议来填充可能出现的日志空隙。
基本算法 最后,Raft 算法采用了一个新的 leader 选举方法,该方法改变了 leader 的选举方式,从而保障了安全性。
Raft 迅速流行[30],并且如今生产系统分为使用 Paxos[3, 5, 31, 33, 36, 38] 和 Raft[2, 8-10, 15, 24, 34] 两个流派。
为了解答 Paxos 和 Raft 哪个是更好的分布式一致性解决方案这个问题,我们必须首先回答这两个算法在达成一致性的方法上具体有什么不同的问题。这不仅能够帮助评估这些算法,也能够允许 Raft 从数十年的对优化 Paxos 的性能[6, 12, 14, 18-20, 26, 27]中受益,反之亦然[1, 37]。
然而,回答这个问题不是一个简单的事情。Paxos 经常被认为不只是一个单独的算法,而是一组解决分布式一致性的算法。Paxos 的通用性(或规格不足,取决于你的观点)意味着对这个算法的描述各种不同,有时相当多的是论文之间的不同。
为了克服这个问题,我们在此提供一个通过对各种 Paxos 版本描述调查而得出的一个简化版本。这个算法(简称为 Paxos)与最初版本的 Paxos 相比,与现在的 Paxos 更为接近[16]。为了将其与决定一个单独的值而不是完全有序的一系列值的 single-decree 区分开,在别处它被叫做 *multi-decree Paxos*,或直接叫 *MultiPaxos*。我们同样使用 Raft 论文的风格和抽象来描述我们简化的算法,以此来在两种不同的算法间进行公平的比较。
我们得出结论:在理解性上两种算法没有特别大的区别,考虑算法的简单性,Raft 的 leader 选举惊人地有效。
2 背景
本文研究了状态机复制环境下的分布式一致性。 状态机复制要求在n台节点之间复制应用程序的确定性状态机,每台节点以相同的顺序应用相同的操作集。这是通过使用由分布式共识算法(通常为 Paxos 或 Raft)管理的复制日志来实现的。
我们假设该系统是非拜占庭[21]的,但是我们假设系统不是是同步的。消息可能任意地延迟,具体的节点可能以任意速度操作,但是我们假设消息交换是可靠且有序的(例如使用 TCP/IP)。我们不依赖时钟同步保障安全性,但是我们为保障活性必须这么做[11]。我们假设这*n*个节点各自有一个 id s (s ∈ {0..(n − 1)})。我们假设操作是唯一的,通过向每个操作添加一对序列号和节点 id 是容易达到的。
3 Paxos 和 Raft 的方法
许多包括 Paxos 和 Raft 在内的共识算法使用一个基于 leader 的方法来解决分布式一致性问题。在更高的层面上来说,这些算法按照以下流程进行:
n 个节点之一被称为 leader。所有状态机的操作都被发往 leader。leader 将操作添加到它们的日志,并且要求其他节点做相同的操作。一旦 leader 知道大多数节点这么做了,它就将这个操作应用到状态机。这个过程一直重复直到 leader 失败后。当 leader 失败时,另一个节点接管成为 leader。这个选举新 leader 的过程至少涉及大多数节点,保证新 leader 不会重写任何之前的应用操作(applied operations)。
我们现在仔细研究 Paxos 和 Raft 的更多细节。读者可能发现参考附录 A 和 B 中提供的 Paxos 和 Raft 的摘要很有帮助。在此我们关注的是 Paxos 和 Raft 的核心元素,由于空间限制,不对垃圾收集、日志压缩、读操作或重配置算法进行更多比较。
3.1 基础
如图1所示,任何时候一个节点可以处于如下三种状态:
Follower 一个职责在于只回复 RPC 的被动状态。
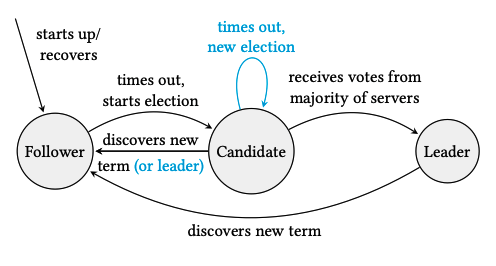
图1,Paxos 和 Raft 节点状态之间的转换。蓝色为 Raft 独有的。
Candidate 一个尝试通过使用 RequestVotes RPC 成为 leader 的活跃状态。
Leader 一个负责使用 AppendEntries RPC 向复制日志添加操作的活跃状态。
最初,节点处于 follwer 状态。该状态一直保持到每个节点在认为 leader 失败时。Follower 随后成为 *candidate*,并且尝试通过使用 RequestVotes RPC 被选举为 leader。如果成功了,该 candidate 成为 leader。新的 leader 必须定期地发送 AppendEntries RPC 作为保活来防止 follwer 超时,并成为 candidate。
每个节点存储一个随时间单调自增的自然数*任期(term)*。最初,每个节点有一个值为0的当前任期。发送的节点(此后称为发送端)的当前任期携带在每个 RPC 中。当一个节点收到一个 RPC,它(此后称为接收端)首先检查其中包含的任期。如果发送端的任期要比接收端的大,那么接收端就会在响应 RPC 之前更新这个任期,如果接收端是 candidate 或 leader,那么它下台成为 follower。如果发送端的任期和接收端的相同,那么接收端会正常回复 RPC。如果发送端的任期比接收端的小,那么接收段就会作出包含它的任期的否定回复。当发送端收到这样的回复时,它就会下台成为 folower 并更新其任期。
3.2 正常的操作
当 leader 收到一个操作时,它会将其添加到当前任期日志的最后。操作和任期以成对的形式组成*日志条目(log entry)*。Leader 通过 AppendEntries RPC 将新日志条目发送到所有其他节点上。每个节点维护一个提交索引(commit index)来记录哪些日志条目是能够安全应用到状态机的,并且响应给 leader 成功接受了这个日志条目。一旦 leader 收到了大多数节点的正确回复,它就会更新其提交索引并将这个操作应用到状态机上。Leader 随后将这个更新过的提交索引加入到随后的 AppendEntries RPC 中。
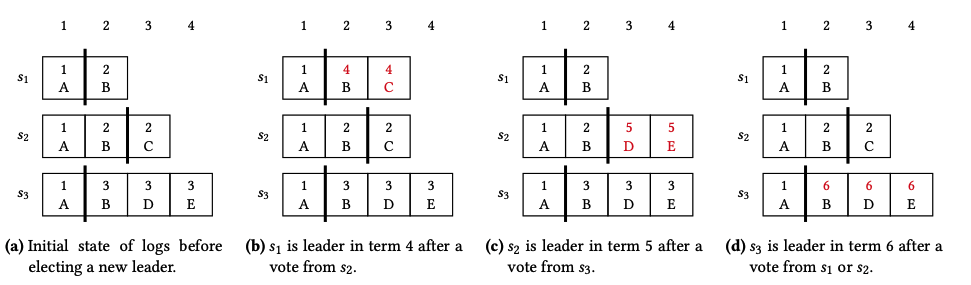
图2,三个运行 Paxos 节点的日志。图(a)为 leader 选举被触发。图(b-d)为 leader 选举完成后、AppendEntries RPC 发送前的日志状态。黑线为提交索引,红字着重标记出日志的变动。
Follower 只有在该日志(或多个日志条目)之前的日志与 leader 的之前的条目相同时才会添加一个日志条目(或一组日志条目)。这能保障日志条目按顺序添加,防止日志空隙,同时保证 follower 将正确的日志条目应用到其状态机上。
3.3 处理 leader 失败
上文的流程只有遇到 leader 失败时才会停止,此时需要建立一个新的 leader。Paxos 和 Raft 采取了不同的方法来解决此问题,所以我们依次描述。
Paxos。一个 follower 在超时时间内没能从收到一个 AppendEntries RPC 之后,它会成为一个 candidate 并更新其任期到下一个,如 t mod n = *s*,其中 t 是下一个任期,n 是 节点数量,s 是 candidate 节点的 id。candidate 会发送 RequestVote RPC 到其他节点上。此 RPC 包含 candidate 的新任期和提交索引。当一个节点收到这个 RequestVote RPC 之后,如果 candidate 的任期比它它的大,那么返回正确的回复。此回复也包含节点在它后续发给 candidate 的提交索引中日志的所有日志条目。
一旦 candidate 从大多数节点上收到 RequestVote 的积极响应,candidate 就必须在保证成为 leader 之前其日志包含所有的提交过的条目。Follower 也是如此。对每个提交索引之后的索引来说,leader 查看其收到的日志条目和它自己的日志。如果 candidate 发现了一个索引的日志条目,那么就会用该条目和新任期更新其自己的日志。如果 leader 发现了同一个索引的多个日志条目,那么它就会用最大、最新的任期更新其日志。例如图2,candidate 现在能够成为一个 leader,并开始复制其日志到其他节点上。
Raft。有一个 follower 没从 leader 收到 AppendEntries 就会产生超时,它会成为一个 candidate 并更新任期。candidate 会发送 RequestVote RPC 到其它所有节点。每个请求都包含此 candidate 的任期和其最后一个日志任期和索引。当一个节点收到 RequestVote 请求时,若 candidate 的任期比其任期更大或相等,并且它还没有在此任期为其他 candidate 投过票,同时 candidate 的日志至少不比该节点的日志的旧,那么它会响应积极的回复。最后这一条标准可以通过确保 candidate 的最后的日志任期比该节点的更大的方式检查,若相同,candidate 的最新索引就比此节点的更大。
一旦 candidate 收到了大多数节点的肯定 RequestVote 回复,candidate 就能成为 leader、并开始复制日志。然而为了安全性,Raft 需要 leader 直到至少一个新任期的日志条目被提交之后才更新其提交索引。
在一个任期中可能有多个 candidate,因此可能出现没有 candidate 获得大多数节点的投票的情况。在此情况下,candidate 超时,同时在下一个任期开始一个新选举。
3.4 安全性
两个算法都保障下面的属性:
定理3.1(状态机安全性)。如果一个节点对其状态机上在一个给定索引上应用了一个日志条目,其他节点不会在相同的索引上应用不同的日志条目。
每个任期最多只有一个 leader,并且 leader 不会重写其自身的日志,我们可以通过下面证明:
定理3.2(Leader 完全性)。如果一个操作 op 在任期 t 被一个 leader 提交到索引 i,那么所有任期大于 t 的 leader 也在索引 i 有相同的操作。
Paxo 证明草图。 假设操作 op 在任期 t 被提交到索引 *i*。我们将大于 t 的任期上使用归纳证明。
基本情况:如果有一个任期 t + 1的 leader,那么 它会在索引 i 有操作 op。
由于任两个大多数有交集,同时消息以任期排序,那么在任期 t ,至少一个操作为 *op*、索引为 i 的节点必定回复了 *t + 1*个 leader 发送的 RequestVote RPC。此节点不能删除或重写此操作,因为自从任期 t 的 leader 以来,它不能积极回复任何一个其他 leader 的 AppendEntries RPC。由于它不会收到任期大于 t 的任何日志条目,故该 leader 将会选择操作 op 。
归纳法情况:假设任何任期在 t + 1 到 t + k 的 leader 都在节点 i 上有操作 op。如果存在任期 t + k + 1 的 leader,那么它会同样在索引 i 上有操作 op。
由于任两个大多数有交集,同时消息以任期排序,那么至少有一个在索引 i 有操作 *op*,并任期在 t 到 t + k 的节点必然积极回复了任期在 t 到 *t + 1*的 leader 发送的 RequestVote RPC。这是因为此节点可能删除或重写此操作,因为除了任期在 t 到 t + k 之外,它没有积极回应任何 leader 的 AppendEntries RPC。通过我们的归纳假说,所有这些 leader 将在索引 i 也有操作 *op*,因此不会重写它。只有 leader 在更大任期收到一个在索引 i 有不同操作的日志条目才会可能选择另一个操作。通过我们的归纳假说,所有的任期在 t 到 t + k 的 leader 同样会在索引 i 处有操作 *op*,因此不会在索引 i 处写入另一个操作。
对 Raft 的证明使用了相同的归纳,但是由于 Raft 对 leader 选举的实现方式不同,细节也因此不同。
4 讨论
Raft 和 Paxos 采用了不同方法实现 leader 选举,这点在表1中总结了。我们在可理解性和效率两个方面进行了比较,依次决定哪个是更优的。
可理解性。 Raft 保证当两个日志包含相同的操作时,那么两者都会有相同的索引和任期。换句话说,每个操作被分配给一个独特的索引-任期对。然而 Paxos 却不是这样,一个操作可能由后来的 leader 分配给更高的任期,像图2b 中操作 B 和 C 中证明的那样。在 Paxos 中,一个提交索引前的日志条目可能被重写。由于日志条目只会这有相同操作的条目重写,所以这是安全的,但是不像 Raft 的方法那样容易理解。
唯一的好处在于,如果日志条目在大多数节点上存在,那么 Paxos 就能够让它安全地提交;但是对 Raft 来说不是这样,它需要日志条目在大多数节点上存在,并且 leader 提交了当前任期后续的日志条目后,leader 才提交之前任期的日志条目。
在 Paxos 中,由 leader 复制的日志条目不是来自当前任期就是已经提交了。我们可以在图2中看到这点,所有 leader 上提交索引之后的日志条目拥有当前任期。在 Raft 中不是这样,leader 可能复制之前任期的未提交条目。
综上,我们认为 Raft 的方法比 Paxos 更容易理解,但是差距没要那么大。
效率。 在 Paxos 中,如果同时多个节点成为 candidate,更大任期的 candidate 将会赢得选举。在 Raft 中,如果多个节点同时成为了 candidate,它们可能在同一个任期中分散投票,并且没有节点会赢得选举。Raft 通过在选举超时后让 follower 统一等待随机额外的时间段来减轻这个情况。我们猜想 Raft 因此在选举时因此会更慢、具有更高的不一致性。
然而,Raft 的 leader 选举阶段比 Paxos 更轻量。Raft 只允许一个有最新日志的 candidate 成为 leader,因此不需要在 leader 选举时发送日志条目。Paxos 不是这样,每个积极的 RequestVote 回复包含 follower 在 candidate 提交索引后面的日志条目。有很多种降低发送的日志条目数量的方法,但是在 leader 的日志不是最新时,对要发送的日志条目来说就是必须的了。
不只是对 RequestVote 回复来说, Paxos 比 Raft 发送更多的日志条目。这两个算法中,一旦一个 candidate 成为了一个 leader,它将会复制其日志到其他的节点上。在 Paxos 中,一个日志条目可能被 leader 分配了一个新任期,因此 leader 可能发送另一个日志条目的副本给一个已经有一个副本的节点。而 Raft 不是这样,每个日志条目在日志中自始至终保持相同的任期。
5 与经典 Paxos 的关系
熟悉 Paxos 的读者可能感觉我们对 Paxos 的描述与那些之前发表的 Paxos 不同,所以我们现在概述我们的 Paxos 算法和那些其他的关系。
角色。 一些对 Paxos 的描述将责任分给三个角色:proposer, acceptor 和 learner[17] 或是 leader, acceptor 和 replica[35]。我们的说明只使用一个角色“节点”来代表所有角色。在说明中使用一个同样叫做 replica[7] 的单一的角色,
| Paxos | Raft | |
|---|---|---|
| 如何保证每个任期至多有一个 leader? | 若 t mod n = *s*,那么一个节点 s 只能在一个任期 t 中成为 candidate。每个任期只会有一个 candidate,所以每个任期只会有一个 leader。 | 一个 follwer 可以在任何任期成为一个 candidate。每个 follower 在每个任期只会向一个 candidate 投票,所以只有一个 candidate 能够获得大多数投票而成为 leader。 |
| 如果保证新 leader 的日志包含所有已提交的日志条目? | 每个 RequestVote 回复包括 follower 的日志条目。一旦一个 candidate 收到了大多数节点的 RequestVote 响应,它会将这些条目和最高的任期写入日志中。 | 一个票保证只有在 candidate 的日志至少与 follower 的同样新时才会投出。这样能够保证一个 candidate 只在它的日志与大多数 follower 同样新时才能成为 leader。 |
| 如何保证 leader 安全地提交之前任期的日志条目? | 之前任期的日志条目与 leader 的任期一同被添加到 leader 的日志中。Leader 随后复制日志条目就像它们是来自该 leader 的任期一样。 | Leader 复制不修改任期就日志条目到其他节点上。leader 直到复制它自己任期随后的日志条目才认为这些日志条目提交了。 |
表1。 Paxos 和 Raft 不同点的总结
术语。 任期也被叫做 views, ballot numbers [35], proposal numbers [17], round number 或 sequence nubmer [7]。我们的 leader 也被叫做 master [7], primary, coordinator 或 distinguished proposer [17]。通常,节点在为 candidate 阶段的这段时间被称为阶段1,节点为 leader 的这段时间被称为阶段2。RequestVote RPC 通常也被叫做阶段1a 和阶段2b 消息[35],准备请求和响应[17]或准备和承诺信息。AppendEntries RPC 也被叫做阶段2a 和阶段2b 消息[35],接收请求和响应[17]或提议和接收信息。
任期。 Paxos 只需要任期完全有序,并且每个节点被分配不相交的任期(为了安全),并且每个节点可以使用比其他所有阶段都大的任期(为了活性)。一些对 Paxos 的描述和我们一样使用循环自然数[7],其他的使用由一个整数和节点 ID 组成的有序对,每个节点只使用包含其自己 ID 的任期。
顺序。 我们的日志条目被按顺序复制和决定。这点不是必要的,但是它能避免填充日志空隙[17]的复杂性。相似地,一些 Paxos 的描述将限制并发决定的数量,这对重配置通常是必要的[17, 35]。
6 总结
Raft 算法被提出是为了解决学习 Paxos 算法带来的大量理解问题。本文中已经论述了 Raft 的可理解性大多数来自于其逻辑抽象和精彩的陈述。通过描述一个与 Raft 使用相同方法的简单 Paxos 算法,我们发现这两个算法只在 leader 选举时有不同。具体是:
(i)Paxos 在节点间区分任期,而 Raft 允许一个 follower 在任何任期成为 candidate,但每个任期只允许为一个 candidate 投票。
(ii)Paxos follower 将会为每个 candidate 投票,而 Raft 中只有 candidate 的日志至少与其一样新才会投票。
(iii)如果一个 leader 拥有之前任期未提交的日志条目,Paxos 将会在当前任期将其复制,而 Raft 将会在其原来的任期将其复制。
Raft 论文声称 Raft 比 Paxos 更易理解和高效。与此相反,我们发现这两个论文在理解性上差距不大,Raft 在 leader 选举上与 Paxos 相比惊人的轻量。这两个我们介绍的算法在设计上都是理想的,并且能够被优化进一步提升性能,尽管代价是增高其复杂性。
参考文献
[1] Arora, V., Mittal, T., Agrawal, D., El Abbadi, A., Xue, X., Zhiyanan, Z., and Zhujianfeng, Z. Leader or majority: Why have one when you can have both? improving read scalability in raft-like consensus protocols. In Proceedings of the 9th USENIX Conference on Hot Topics in Cloud Computing (USA, 2017), HotCloud’17, USENIX As- sociation, p. 14.
[2] Atomix. https://atomix.io.
[3] Baker, J., Bond, C., Corbett, J. C., Furman, J., Khorlin, A., Lar-
son, J., Leon, J.-M., Li, Y., Lloyd, A., and Yushprakh, V. Megastore: Providing scalable, highly available storage for interactive services. In Proceedings of the Conference on Innovative Data system Research (CIDR) (2011), pp. 223–234.
[4] Boichat,R.,Dutta,P.,Frølund,S.,andGuerraoui,R.Deconstruct- ing paxos. SIGACT News 34, 1 (Mar. 2003), 47–67.
[5] Burrows, M. The chubby lock service for loosely-coupled distributed systems. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation (USA, 2006), OSDI ’06, USENIX Associa- tion, pp. 335–350.
[6] Camargos, L. J., Schmidt, R. M., and Pedone, F. Multicoordinated paxos. In Proceedings of the Twenty-Sixth Annual ACM Symposium on Principles of Distributed Computing (New York, NY, USA, 2007), PODC ’07, Association for Computing Machinery, pp. 316–317.
[7] Chandra, T. D., Griesemer, R., and Redstone, J. Paxos made live: An engineering perspective. In Proceedings of the Twenty-Sixth An- nual ACM Symposium on Principles of Distributed Computing (New York, NY, USA, 2007), PODC ’07, Association for Computing Machin- ery, pp. 398–407.
[8] CockroachDB. https://www.cockroachlabs.com.
[9] Consul by hashicorp. https://www.consul.io.
[10] etcd. https://coreos.com/etcd/.
[11] Fischer, M. J., Lynch, N. A., and Paterson, M. S. Impossibility of dis-
tributed consensus with one faulty process. J. ACM 32, 2 (Apr. 1985),
374–382.
[12] Gafni, E., and Lamport, L. Disk paxos. In Proceedings of the 14th In-
ternational Conference on Distributed Computing (Berlin, Heidelberg,
2000), DISC ’00, Springer-Verlag, pp. 330–344.
[13] Herlihy, M. P., and Wing, J. M. Linearizability: A correctness con-
dition for concurrent objects. ACM Trans. Program. Lang. Syst. 12, 3
( July 1990), 463–492.
[14] Kraska, T., Pang, G., Franklin, M. J., Madden, S., and Fekete, A.
Mdcc: Multi-data center consistency. In Proceedings of the 8th ACM European Conference on Computer Systems (New York, NY, USA, 2013), EuroSys ’13, Association for Computing Machinery, pp. 113–126.
[15] Kubernetes: Production-grade container orchestration. https://kubernetes.io.
[16] Lamport, L. The part-time parliament. ACM Trans. Comput. Syst. 16, 2 (May 1998), 133–169.
[17] Lamport, L. Paxos made simple. ACM SIGACT News (Distributed Computing Column) 32, 4 (Whole Number 121, December 2001) (De- cember 2001), 51–58.
[18] Lamport, L. Generalized consensus and paxos. Tech. Rep. MSR-TR- 2005-33, Microsoft, March 2005.
[19] Lamport, L. Fast paxos. Distributed Computing 19 (October 2006), 79–103.
[20] Lamport, L., and Massa, M. Cheap paxos. In Proceedings of the 2004 International Conference on Dependable Systems and Networks (USA, 2004), DSN ’04, IEEE Computer Society, p. 307.
[21] Lamport, L., Shostak, R., and Pease, M. The byzantine generals problem. ACM Trans. Program. Lang. Syst. 4, 3 (July 1982), 382–401.
[22] Lampson, B. The abcd’s of paxos. In Proceedings of the Twentieth Annual ACM Symposium on Principles of Distributed Computing (New York, NY, USA, 2001), PODC ’01, Association for Computing Machin- ery, p. 13.
[23] Lampson,B.W.Howtobuildahighlyavailablesystemusingconsen- sus. In Proceedings of the 10th International Workshop on Distributed Algorithms (Berlin, Heidelberg, 1996), WDAG ’96, Springer-Verlag, pp. 1–17.
[24] M3: Uber’s open source, large-scale metrics platform for prometheus. https://eng.uber.com/m3/.
[25] Meling, H., and Jehl, L. Tutorial summary: Paxos explained from scratch. In Proceedings of the 17th International Conference on Prin- ciples of Distributed Systems - Volume 8304 (Berlin, Heidelberg, 2013), OPODIS 2013, Springer-Verlag, pp. 1–10.
[26] Moraru, I., Andersen, D. G., and Kaminsky, M. There is more con- sensus in egalitarian parliaments. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles (New York, NY, USA, 2013), SOSP ’13, Association for Computing Machinery, pp. 358–372.
[27] Moraru, I., Andersen, D. G., and Kaminsky, M. Paxos quorum leases: Fast reads without sacrificing writes. In Proceedings of the ACM Symposium on Cloud Computing (New York, NY, USA, 2014), SOCC ’14, Association for Computing Machinery, pp. 1–13.
[28] Ongaro, D., and Ousterhout, J. In search of an understandable consensus algorithm. In Proceedings of the 2014 USENIX Conference on USENIX Annual Technical Conference (USA, 2014), USENIX ATC’14, USENIX Association, pp. 305–320.
[29] Prisco, R. D., Lampson, B. W., and Lynch, N. A. Revisiting the paxos algorithm. In Proceedings of the 11th International Workshop on Dis- tributed Algorithms (Berlin, Heidelberg, 1997), WDAG ’97, Springer- Verlag, pp. 111–125.
[30] The raft consensus algorithm. https://raft.github.io.
[31] Ramakrishnan, R., Sridharan, B., Douceur, J. R., Kasturi, P., Krishnamachari-Sampath, B., Krishnamoorthy, K., Li, P., Manu, M., Michaylov, S., Ramos, R., and et al. Azure data lake store: A hyperscale distributed file service for big data analytics. In Proceed- ings of the 2017 ACM International Conference on Management of Data
(New York, NY, USA, 2017), SIGMOD ’17, Association for Computing
Machinery, pp. 51–63.
[32] Schneider, F. B. Implementing fault-tolerant services using the state
machine approach: A tutorial. ACM Comput. Surv. 22, 4 (Dec. 1990),
299–319.
[33] Schwarzkopf, M., Konwinski, A., Abd-El-Malek, M., and Wilkes,
J. Omega: Flexible, scalable schedulers for large compute clusters. In
Proceedings of the 8th ACM European Conference on Computer Systems
(New York, NY, USA, 2013), EuroSys ’13, Association for Computing
Machinery, pp. 351–364.
[34] Trillian: General transparency. https://github.com/google/trillian/.
[35] Van Renesse, R., and Altinbuken, D. Paxos made moderately com-
plex. ACM Comput. Surv. 47, 3 (Feb. 2015).
[36] Verma, A., Pedrosa, L., Korupolu, M., Oppenheimer, D., Tune, E.,
and Wilkes, J. Large-scale cluster management at google with borg. In Proceedings of the Tenth European Conference on Computer Systems (New York, NY, USA, 2015), EuroSys ’15, Association for Computing Machinery.
[37] Zhang, Y., Ramadan, E., Mekky, H., and Zhang, Z.-L. When raft meets sdn: How to elect a leader and reach consensus in an unruly network. In Proceedings of the First Asia-Pacific Workshop on Network- ing (New York, NY, USA, 2017), APNet’17, Association for Computing Machinery, pp. 1–7.
[38] Zheng, J., Lin, Q., Xu, J., Wei, C., Zeng, C., Yang, P., and Zhang, Y. Paxosstore: High-availability storage made practical in wechat. Proc. VLDB Endow. 10, 12 (Aug. 2017), 1730–1741.